上下文窗口怎么算的:会忘记前面说的吗
📍 进阶 4/10 · 上一篇:← CLAUDE.md:让它一开口就懂你的项目

你一定会遇到的诡异瞬间
Section titled “你一定会遇到的诡异瞬间”跟 Claude Code 聊一个下午,某个时刻你输入:
“把刚才那个 endpoint 的命名再改一下,跟开头你提的那个风格一致。”
它愣了一秒,然后说:
“抱歉,我没看到「刚才那个 endpoint」的上下文。能再贴一下吗?”
你皱眉。你明明 1 小时前刚跟它讨论过。它怎么就忘了?
不是 AI 抽风,是它的「短期记忆」装满了。这就是上下文窗口(context window)的核心问题。
读懂这一篇,你会知道:
- 怎么看你现在用了多少记忆(/context 命令)
- 快满了会发生什么(auto-compact 自动压缩)
- 三种主动给它腾地方的方法
「上下文」到底是什么
Section titled “「上下文」到底是什么”
简单粗暴的定义:
**Claude 在一次对话里”能同时看到的所有文字”**就是上下文。
它包括:
- 你的每一条问话
- 它的每一条回复
- 你让它读过的所有文件内容
- 它跑过的命令的输出
- 你的 CLAUDE.md 文档
- 它使用的工具调用记录
全部加起来,会被换算成一个数字单位叫 token(可以粗略理解为”一个字 ≈ 1.5 个 token”——中文 1 字约 1-2 token,英文 1 单词约 1-2 token)。
模型一次能装下的 token 总数 = 上下文窗口大小。
超出这个数,前面的对话就会被挤出去,模型就「忘事」了。
主流模型容量对比
Section titled “主流模型容量对比”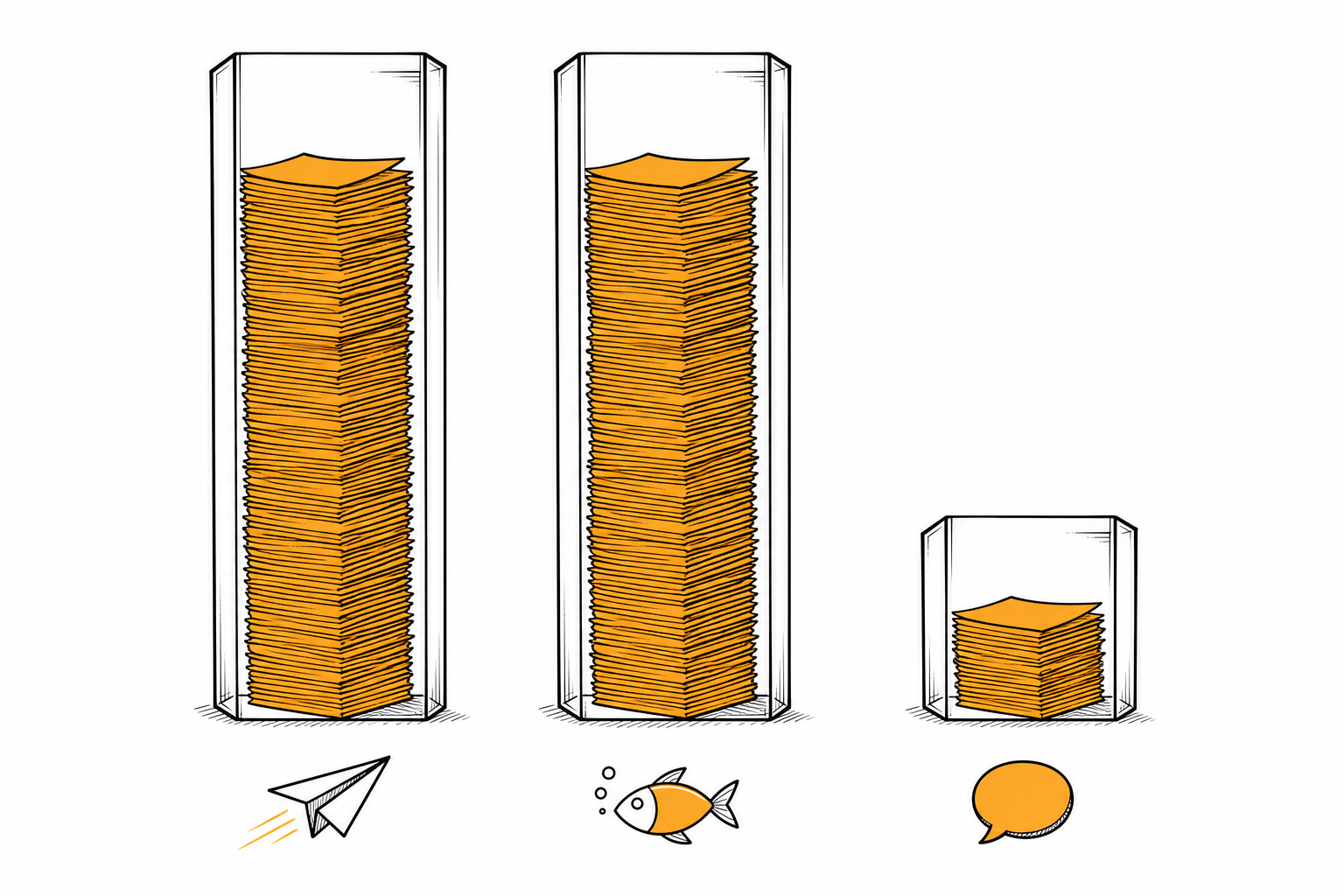
| 模型 | 上下文窗口 | 用户体感 |
|---|---|---|
| Claude Opus 4.7 | 1,000,000 token | 一整天聊不完(≈ 一本《红楼梦》) |
| Claude Sonnet 4.6 / Haiku 4.5 | 200,000 ~ 1M | 几小时到一整天(≈ 半本到一本《红楼梦》) |
| DeepSeek V4 | 128,000 ~ 1,000,000 | 几小时到一整天(看具体模型) |
| ChatGPT 4 / 4 Turbo | 128,000 | 一两个小时(≈ 1/8 本《红楼梦》/ 半本《活着》) |
| DeepSeek R1 / V3 | 128,000 | 一两个小时(≈ 半本《活着》) |
| 豆包 / 文心 / 通义 | 32,000 ~ 128,000 | 半小时到一小时就会忘事(比 ChatGPT 还小) |
关键 insight:
- Claude Opus 4.7 的 1M context 是目前民用 AI 的天花板。聊一整天都不太可能撑满。
- DeepSeek V4 的 1M 主要走 API 调用,Claude Code + DeepSeek 配置默认就走它。
- 国内 chat 网站(豆包 / 文心)的 32k-128k——聊半小时就会忘事,所以对话型 AI 很难做长任务。
这就是为什么 Claude Code 能做出豆包做不到的事:它的「单次任务记忆量」高一个量级。
怎么看你现在用了多少:/context
Section titled “怎么看你现在用了多少:/context”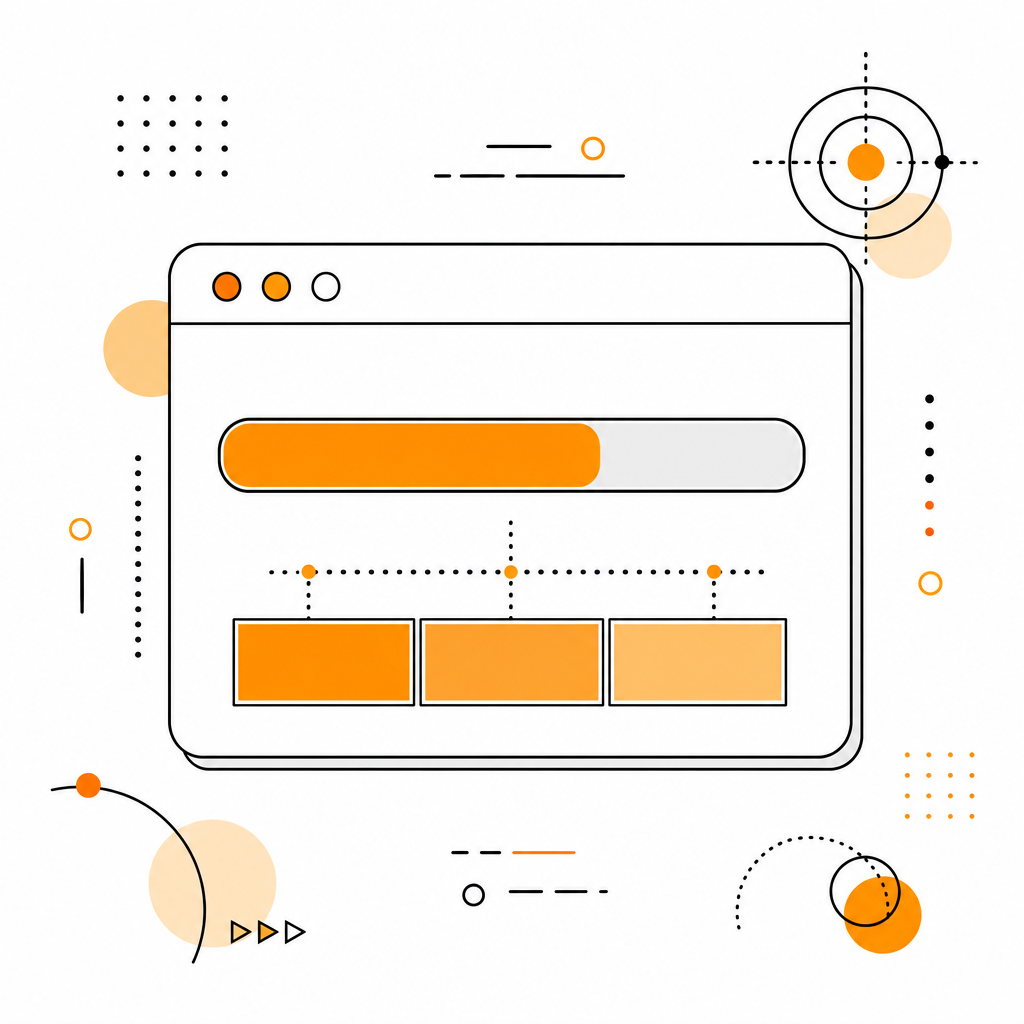
在 Claude Code 内输入:
/context会输出一段像这样的报告:
Context Usage:━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[████████████░░░░░░░░░░░░░░░░░░░] 38% (382k / 1.0M tokens)─────────────────────────────────────Breakdown: · System prompt 12k · CLAUDE.md 8k · Tool definitions 15k · Conversation 287k · File reads 60k─────────────────────────────────────怎么读这个报告:
- 38% 用完了 — 还很安全,继续聊
- 超过 70% — 开始警惕,考虑 /compact
- 超过 90% — 紧急,马上 /compact 或 /clear
- 超过 95% — Claude Code 会自动触发 compact
Breakdown 看哪一块占得最大:
- Conversation 大 → 聊得太长,该 /compact
- File reads 大 → 读了太多大文件,该退出去重开
- CLAUDE.md 大 → 你 CLAUDE.md 写臃肿了,该精简
容量满了会发生什么
Section titled “容量满了会发生什么”
Claude Code 不会让你「装超」就死掉,它有两层保护:
🟢 第一层:Auto-Compact(自动压缩)
Section titled “🟢 第一层:Auto-Compact(自动压缩)”到达 ~95% 时,Claude Code 会自动把前面的对话总结成一段短描述,腾出空间。
你看到的体感:
- 对话区出现一条横幅:“对话已自动压缩”
- 它接下来的回复记得”大致内容”,但不记得每一句原话
类比:就像你把 30 页的会议纪要总结成 1 页 outline——核心议题还在,但具体话术丢了。
🟡 第二层:Hard Truncate(硬截断)
Section titled “🟡 第二层:Hard Truncate(硬截断)”如果连 auto-compact 都不够(比如你一直在让它读超大文件),它会直接丢掉最早的对话。
体感:
- 它彻底忘了一开始你说过什么
- 你早期定的「不许加注释」规则 — 失效
- 你 30 分钟前贴的代码 — 它读不到了
这是为什么 CLAUDE.md 重要——CLAUDE.md 是「常驻区」,不会被 truncate。所有「长期规则」写进 CLAUDE.md,不要塞对话。
三种主动省 context 的方法
Section titled “三种主动省 context 的方法”
💧 方法 1:/compact 主动压缩
Section titled “💧 方法 1:/compact 主动压缩”/compact手动触发一次压缩。当 /context 显示 70%+ 时,主动跑一次。
好处:
- 比 auto-compact 更可控(你选时机)
- 不会突然在你正聊到一半时打断
适合:聊得很 deep、不想丢上下文但需要腾地方。
📒 方法 2:/clear 开新一轮
Section titled “📒 方法 2:/clear 开新一轮”/clear清空整个对话历史,但保留 CLAUDE.md 跟项目设置。
好处:
- 100% 干净的环境
- 速度最快
适合:
- 换主题(刚才在聊简历,现在要聊代码)
- 上一轮已经收尾(任务完成、给你结果了)
- context 用到 90%+,与其压缩不如重开
🚨 重点:/clear 后,前面的对话彻底没了。先把重要结论保存到文件再 /clear。
🪟 方法 3:开多个 session 并行
Section titled “🪟 方法 3:开多个 session 并行”新手忽略的一招——Claude Code 不是只能开一个对话。
你可以:
- Terminal 窗口 A 跑「改简历」
- Terminal 窗口 B 跑「整理发票」
- Terminal 窗口 C 跑「写周报」
3 个独立 context,互不干扰。
每个任务只占自己的 context,不会互相挤。
桌面 App 版甚至有「Worktree 隔离」——每个 session 在独立的 git 分支跑,改完不影响主线。详见后续文章。
三个新手必踩的坑
Section titled “三个新手必踩的坑”❌ 坑 1:开一个对话从早聊到晚
Section titled “❌ 坑 1:开一个对话从早聊到晚”“我从早 10 点跟它聊到下午 3 点,改简历 → 改代码 → 整理发票 → 写周报 → 又改了次简历…”
5 个完全不同的任务塞同一个 context,到下午时早上的规则它全忘了。
修正:任务切换 = 新建 session 或 /clear。
❌ 坑 2:让它读 10 个大文件
Section titled “❌ 坑 2:让它读 10 个大文件”“帮我读 ~/Documents/合同/ 里这 10 个 PDF,逐份分析。”
10 个 PDF 每个 50 页 = 几百 k token 直接占满 context,后面分析时它已经「记不住」第 1 份了。
修正:分批读、分析完一份保存结果再读下一份。或者让它先扫目录列清单,你挑出真正要分析的 3-5 份。
❌ 坑 3:CLAUDE.md 越写越长
Section titled “❌ 坑 3:CLAUDE.md 越写越长”“CLAUDE.md 我现在 800 行了,什么都往里塞。”
每次启动,这 800 行都会被加载进 context——你还没开口就已经消耗了几十 k token。
修正:CLAUDE.md 控制在 200 行内,把过时规则删掉,把模块特定规则放到对应子目录的 CLAUDE.md。
一个实用 checklist
Section titled “一个实用 checklist”每天用 Claude Code 之前,养成这个习惯:
- ✅ 开干前:
/context看一眼,确认你新开的 session 是干净的 - ✅ 聊到 70%:主动
/compact - ✅ 任务完成 / 换主题:
/clear,开新一轮 - ✅ /cost 跟 /context 关联看:context 大 → token 多 → 烧钱多
- ✅ CLAUDE.md 每月精简一次:删过时规则,合并重复条目
做到这 5 条,你不会因为 context 问题被它「失忆」坑到。
读完这篇你应该理解 上下文窗口的本质 + 三种省 context 的方法 + 怎么看用量。
接下来:
→ 一次说错可以撤回:checkpoint 用法 —— Claude 改坏了一键回滚
→ 出错怎么办:常见报错排雷大全 —— 速查表
想第一时间收到,可以收藏 niuxue.org 主页。
如果你今天发现 /context 用到 90% 都没崩,可以发邮箱 [email protected],我们感兴趣你聊了啥这么扛造。
评论
不记名、不需要注册——不要邮箱,不要手机号,不要任何身份信息,填个昵称就能留言。放心说。