AI agent 是怎么思考的:ReAct 模式
📍 Agent 通用知识 1/X · 上一板块:← AI 端到端流程

一个让人困惑的小问题
Section titled “一个让人困惑的小问题”你打开 ChatGPT 网页版问:
今天多伦多天气怎样?
它回答:
抱歉,我无法访问实时信息。
你又打开 Claude Code 问同一句话。它回答:
今天多伦多 18 度,晴天 🌞
底层是同一类大模型,差别在哪?
差别在:聊天机器人只会出文字;Claude Code 会先想一下「这事儿我得查」,真的去网上查,然后根据结果回答你。
这个「想一下 → 真的动手 → 看结果 → 再想下一步」的循环,就是这一篇要讲的 ReAct 模式。它是 2022 年普林斯顿大学和谷歌团队提出的范式,现在 Claude Code / 扣子 / Trae,几乎所有能「自己干活」的 AI 工具,底层都在跑这个循环。
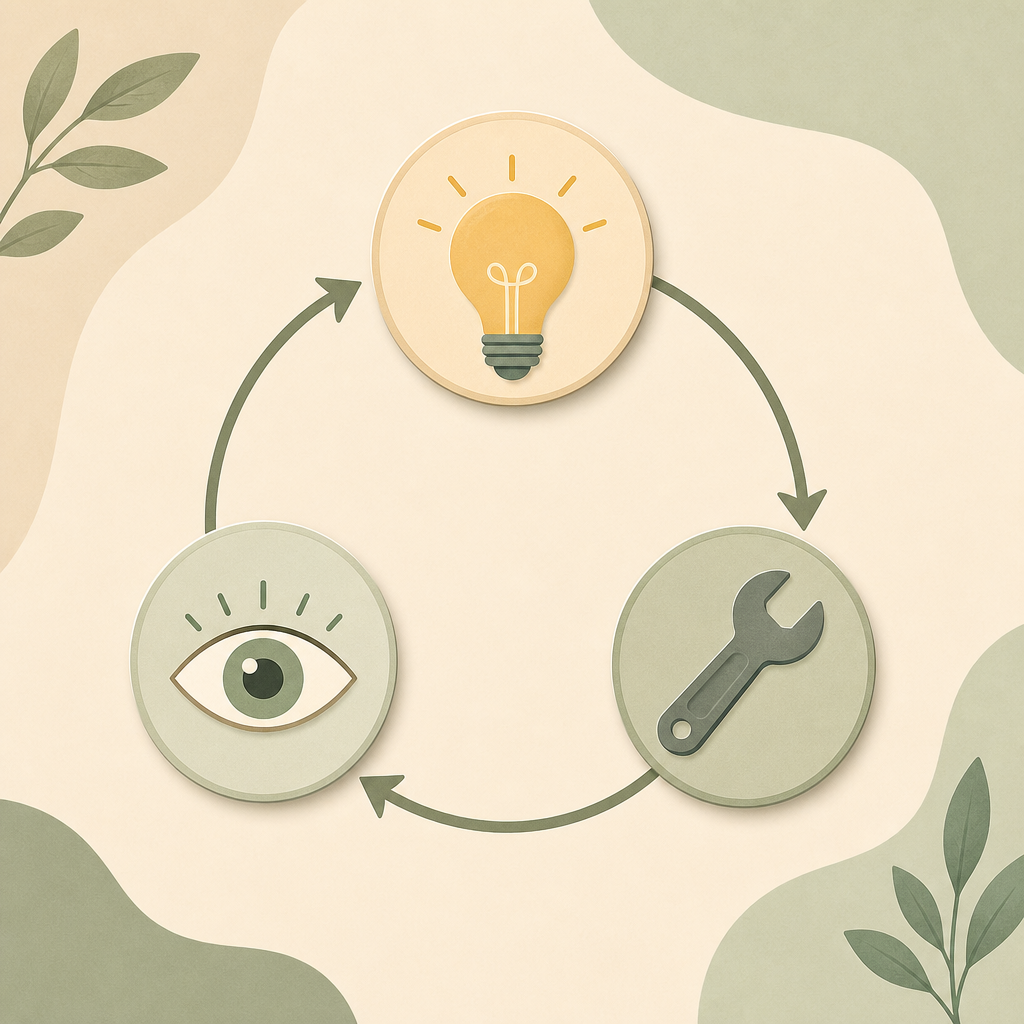
ReAct = 推理(Reason)+ 行动(Act)+ 观察(Observation)的循环。
AI agent 每走一步都在心里默念:
- 我接下来应该干啥?(思考)
- 那就动手 —— 调一个工具(行动)
- 看看结果对不对?(观察)
- 回到第 1 步,继续想下一步。
直到任务完成。
ReAct 这个词是「Reasoning(推理) + Acting(行动)」拼出来的,英文叫 ReAct,中文也常直接读「瑞-act」。

核心:三步循环
Section titled “核心:三步循环”ReAct 把 agent 的每一轮分成三段:
| 步骤 | 名字 | 干什么 |
|---|---|---|
| 1 | 思考(Thought) | 大模型在脑子里想:「现在该干啥?」 |
| 2 | 行动(Action) | 调一个工具(搜网页 / 跑命令 / 读文件 / 写文件) |
| 3 | 观察(Observation) | 拿到工具的返回结果,作为下一轮的输入 |
然后回到第 1 步,再想下一步。
听起来很抽象?来看真实例子。
真实拆解:Claude Code 跑一个任务
Section titled “真实拆解:Claude Code 跑一个任务”你给 Claude 说:
看下这个项目有没有 README,没有就帮我写一个
它内部跑的循环是这样的(我把每一轮拆开):
第 1 轮
- 思考:「先看看项目里有没有 README 文件」
- 行动:调 Bash 工具,跑
ls README* - 观察:返回
ls: README*: No such file or directory
第 2 轮
- 思考:「没找到,那需要看一下项目长啥样再写」
- 行动:调 Bash 工具,跑
ls -la - 观察:看到
package.json、src/、test/三个东西
第 3 轮
- 思考:「是 Node 项目,看下 package.json 知道这是干啥的」
- 行动:调 Read 工具,读
package.json - 观察:得到「这是一个画 SVG 的库」
第 4 轮
- 思考:「信息够了,可以写 README 了」
- 行动:调 Write 工具,写
README.md - 观察:写入成功
第 5 轮
- 思考:「任务完成了」
- 输出给你:「我看了下项目,是个 SVG 库,README 我写好了,主要包括…」

关键点:它没有事先规划完整流程,而是每走一步都根据当前看到的情况决定下一步。
这就是 ReAct 的精髓 —— 见招拆招,而不是「先想 10 步再开始」。
跟普通聊天机器人对比
Section titled “跟普通聊天机器人对比”| 维度 | 聊天机器人(早期 ChatGPT) | ReAct agent(Claude Code) |
|---|---|---|
| 能干什么 | 回答你的问题 | 帮你完成任务 |
| 拿数据 | 只能用训练时见过的 | 现场调工具拿最新的 |
| 出错怎么办 | 直接编一个(幻觉) | 看到报错 → 再想 → 再试 |
| 多步任务 | 一次答完不能反复 | 想多少轮就想多少轮 |
| 调工具 | 没有这个能力 | 调 Bash / Read / Write / WebFetch 等 |
为啥不直接告诉 AI「先 A 再 B」?
Section titled “为啥不直接告诉 AI「先 A 再 B」?”你可能问:我直接跟它说步骤不就行了?
可以,但有局限:
- 任务一复杂就说不清:「帮我清理一下这个项目里没用的依赖」—— 哪些没用?得它自己看才知道
- 中途结果会变:跑命令报错了,下一步就得改方案,事先没法写死
- 真实世界是不确定的:网页加载失败、接口限流、文件不存在 —— 都要现场决策
ReAct 的精髓就在「先做一步,看结果,再决定下一步」。
这个思路其实跟人工作很像 —— 你做一件事不会一开始就规划到死,通常是走一步看一步,根据现场反馈调整。
现在的进化:从 ReAct 到 Tool Use
Section titled “现在的进化:从 ReAct 到 Tool Use”ReAct 2022 年提出的时候,是用纯提示词(prompt)实现的 —— 让模型在输出里手动写:
Thought: 我得先看下文件Action: ls -laObservation: package.json, src/, test/Thought: 是 Node 项目...然后用程序解析这串文本,把 Action: 后面那段拿去真的跑命令。
听起来很笨?确实有点笨。问题:
- 模型可能漏写「Action:」前缀
- 解析器可能崩
- 整个流程靠字符串黏起来,不稳定
到 2024 年,OpenAI / Anthropic 把这玩意儿做成了官方接口 —— 叫 Tool Use(工具调用)或 Function Calling:
- 模型直接返回结构化数据:「我要调哪个工具,参数是啥」
- 不用 prompt 里写「Thought:」这种字符串
- 更稳定、更省 token、更快
Claude Code 用的就是 Anthropic 的 Tool Use 接口,底层还是 ReAct 范式(思考→行动→观察),只是包装更顺手。

再进化:Subagent 把单线变成多线
Section titled “再进化:Subagent 把单线变成多线”到 2025 年,Subagent(子智能体)把单线 ReAct 变成多线:
- 主 agent 跑 ReAct 循环
- 它可以喊一个 sub-agent,sub-agent 也跑自己的 ReAct 循环
- 多个 ReAct 循环同时进行
这就是为啥 Claude Code 能一边查 bug 一边写测试一边读文档 —— 多个独立的 ReAct 实例并行跑。

详细玩法可以看 Subagents(子智能体) 那一篇。
ReAct = AI 学会「边想边做」的最早一招。
理解了这个三步循环,你就懂:
- 为啥 Claude Code 能自己做决定(每一轮 Thought 都在决策)
- 为啥它有时候会重试 / 换工具(上一轮 Observation 告诉它失败了)
- 为啥同样一句话,普通聊天机器人答不出来,Claude Code 能给你结果(它有 Action 环节)
所有 agent 工具的底层 —— Claude Code、扣子、Trae、文心 agent、通义 agent —— 都是这个三步循环在跑,差别只是工具集和包装。
牛学板块导航
Section titled “牛学板块导航”- 上一板块:← AI 端到端流程
- 本板块:Agent 通用知识
- 1/X AI agent 是怎么思考的:ReAct 模式(就是这一篇)
- 2/X 给 Agent 配齐 4 类 API 工具
- 3/X(规划中)MCP 详解
- 4/X(规划中)Memory:让 agent 记住你
- 5/X(规划中)多 agent 编排
- 下一篇:给 Agent 配齐 4 类 API 工具 →
- 这个范式怎么用到 Claude Code 进阶功能?→ Subagents(子智能体) / Hooks(钩子)
- 想看 Claude 怎么处理工具调用?→ 让 Claude 跑命令:三种权限模式
- 想自己撸一个 ReAct?→ 原论文 ReAct: Synergizing Reasoning and Acting in Language Models(Yao 等,2022)
评论
不记名、不需要注册——不要邮箱,不要手机号,不要任何身份信息,填个昵称就能留言。放心说。