AI 是怎么「学会」+ 怎么「干活」的(端到端流程)
📍 认识 AI 4/4 · 上一篇:← AI 圈在卷什么 · 完结篇
一台 AI 的「一生」
Section titled “一台 AI 的「一生」”
你每天用的 ChatGPT、豆包、Claude Code,看起来就是一个聊天框。但它背后有两条流水线——
- 造它的流水线:怎么从一堆数据学会说话、做事
- 用它的流水线:你按下回车之后,怎么从一个问题到一个结果
前面 3 篇文章已经讲过零碎的概念(token、预训练、RLHF、Agent……)。这一篇把它们串成一根线——一头是「数据」,另一头是「你拿到的答案」,中间发生了什么,全程跑一遍。
看完这一篇,你脑子里就有了完整的「AI 一生地图」。
Part 1|AI 是怎么造出来的(训练流水线)
Section titled “Part 1|AI 是怎么造出来的(训练流水线)”一个能用的 AI 模型,从「啥都没有」到「上线给你用」,要走 5 步——
Step 1:数据收集
Section titled “Step 1:数据收集”
第一步永远是收数据。
OpenAI、Anthropic、DeepSeek 这种公司,会从 4 个地方搞资料:
- 公开互联网:维基百科、新闻网、博客、论坛、StackOverflow、Reddit、GitHub 代码……基本上「能爬到的全爬」
- 公开数据集:Common Crawl(一个开源的「全网快照」)、各种学术数据集
- 图书 / 论文:买版权 + 扫电子书
- 付费授权数据:跟新闻媒体(如纽约时报、华尔街日报)、出版商、Reddit 等买内容授权
多少量:GPT-3 训练用了约 45TB 文本,相当于读了 4500 万本平均长度的小说。
打个比方:你要培养一个百科全书级别的孩子,你得让他把人类历史上写下来的东西大部分读一遍。
Step 2:预训练(最贵那一步)
Section titled “Step 2:预训练(最贵那一步)”把上一步的几十 TB 数据丢进神经网络,让它一次次预测「下一个 token 是什么」(上一篇讲过的)。
这一步是整个流程最贵的:
- 用几千张顶级 GPU(H100、B200 这种,单卡 30 万人民币起)
- 跑几周到几个月不间断
- 电费 + 卡折旧 + 人工,一次预训练成本 5000 万到几个亿人民币
这就是为什么训出一个最顶级的大模型只有 OpenAI、Anthropic、Google、Meta、字节、阿里、DeepSeek 这些能烧得起钱的公司能做。
训完得到的叫「基础模型」——能力够,但不会跟人对话。
Step 3:微调
Section titled “Step 3:微调”刚训完的基础模型像一个饱读群书但不太会做人的怪学生。
「微调」(fine-tune)就是再训练一小段,让它学会对话格式、礼貌、特定任务模式。
成本比预训练低 3-4 个数量级——可能几千到几十万人民币就能微调一次。
Step 4:RLHF / 对齐
Section titled “Step 4:RLHF / 对齐”光会格式还不够,模型还得学会跟人说话——不冷冰冰、不绕弯子、不胡说八道。
这一步用的是 RLHF(人类反馈强化学习,上一篇详细讲过):
- 雇真人对模型回答打分
- 用打分数据训一个「打分小模型」
- 用打分小模型反过来调教主模型
完成后,模型从「能生成文字的工具」变成「懂得跟人对话的助手」。
这一步还会做「对齐」(alignment)——让模型拒绝危险请求(教你做炸药、教你自杀)、不歧视、不撒谎。
Step 5:评估 + 部署
Section titled “Step 5:评估 + 部署”模型训好了,不能直接上线。要先做两轮把关:
- 能力评估:跑几十个标准测试集(数学、编程、推理、中文、安全),看分数有没有达标
- 红队测试(red teaming):雇专业团队专门尝试让模型做坏事——骂人、教犯罪、泄露训练数据、绕过安全策略——所有漏洞补上才能上线
过了关,模型就被部署到 API 服务器上——这时候你和我才能调用它。
—
整个 Part 1 大约 6-12 个月,烧几个亿。每代模型出新版(GPT-4 → GPT-5、Claude Sonnet → Opus 4.7)都要重跑一遍这条流水线。
Part 2|AI 是怎么被你用的(使用流水线)
Section titled “Part 2|AI 是怎么被你用的(使用流水线)”模型上线之后,你跟它打交道,其实也走 4 步。大多数人停在第 1-2 步,导致 AI 用得很烂。

Step 1:选对模型
Section titled “Step 1:选对模型”你以为「我用的就是 ChatGPT」,其实 ChatGPT 内部有好几个模型可选——GPT-4o(快但不深)、GPT-5(更深更慢)、o3(推理强)……每个适合不同场景。
普通人最容易踩的坑:永远只用默认那个,遇到复杂任务硬让它做,结果当然差。
简单原则:
| 任务 | 选什么模型 |
|---|---|
| 简单聊天、查信息 | 便宜快速版(GPT-4o-mini、豆包) |
| 写报告、改文案、整理资料 | 中档(GPT-5、Claude Sonnet、deepseek-chat) |
| 复杂推理 / 难题 debug | 推理模型(DeepSeek R1、OpenAI o3、Claude extended thinking) |
| 看图、看视频 | 多模态模型(Claude / Gemini / GPT-4V) |
Step 2:写好 prompt
Section titled “Step 2:写好 prompt”你输入的那段话叫 prompt(提示词)。这是普通人和高手 AI 用户最大的差距所在。
烂 prompt:「写个邮件」 好 prompt:「帮我给 HR 写一封请假邮件,3 段以内,理由是孩子发烧 39 度,口气客气但简洁,收件人是张经理。」
差别在 4 件事:
- 目标具体:要什么(不是「写个邮件」是「写一封请假邮件」)
- 上下文给足:背景信息(理由是啥、收件人是谁)
- 约束明确:长度 / 风格 / 格式
- 角色 / 口吻:客气还是强硬
写好 prompt 这件事大到可以专门写一本书。下一篇 first-prompt 会展开。
Step 3:看输出
Section titled “Step 3:看输出”模型给你结果后,不要傻乎乎全盘接受。
养成一个习惯:快速扫一遍输出,判断对不对——
- 信息有没有错(特别是数字、时间、人名)
- 逻辑有没有断
- 风格符不符合你要的
- 有没有「AI 味」太重
模型会自信地胡说八道——这就是上一篇讲的「幻觉」。养成「先怀疑、再使用」的习惯,能避开 90% 的坑。
Step 4:迭代
Section titled “Step 4:迭代”第一版输出不对?大多数人会做的事是:关掉重开或者人肉改。
正确做法:跟 AI 说哪里不对,让它改。
举例:
- 「这一段太啰嗦了,缩短一半」
- 「这个数据不对,2023 年中国 GDP 是 17.7 万亿美元不是 18.6」
- 「换个更礼貌的口气」
模型记得你前面说的(上下文窗口),可以在同一段对话里反复磨——这叫「迭代」。
高手和新手最大的差别就在这里:高手 5 轮迭代出完美结果,新手第 1 轮觉得不行就放弃。
两条线在哪里交汇
Section titled “两条线在哪里交汇”到这里你应该看清楚了——
训练流水线走了 6-12 个月,烧几个亿。模型部署上线。
使用流水线就是你每天那 4 步:选模型 → 写 prompt → 看输出 → 迭代。
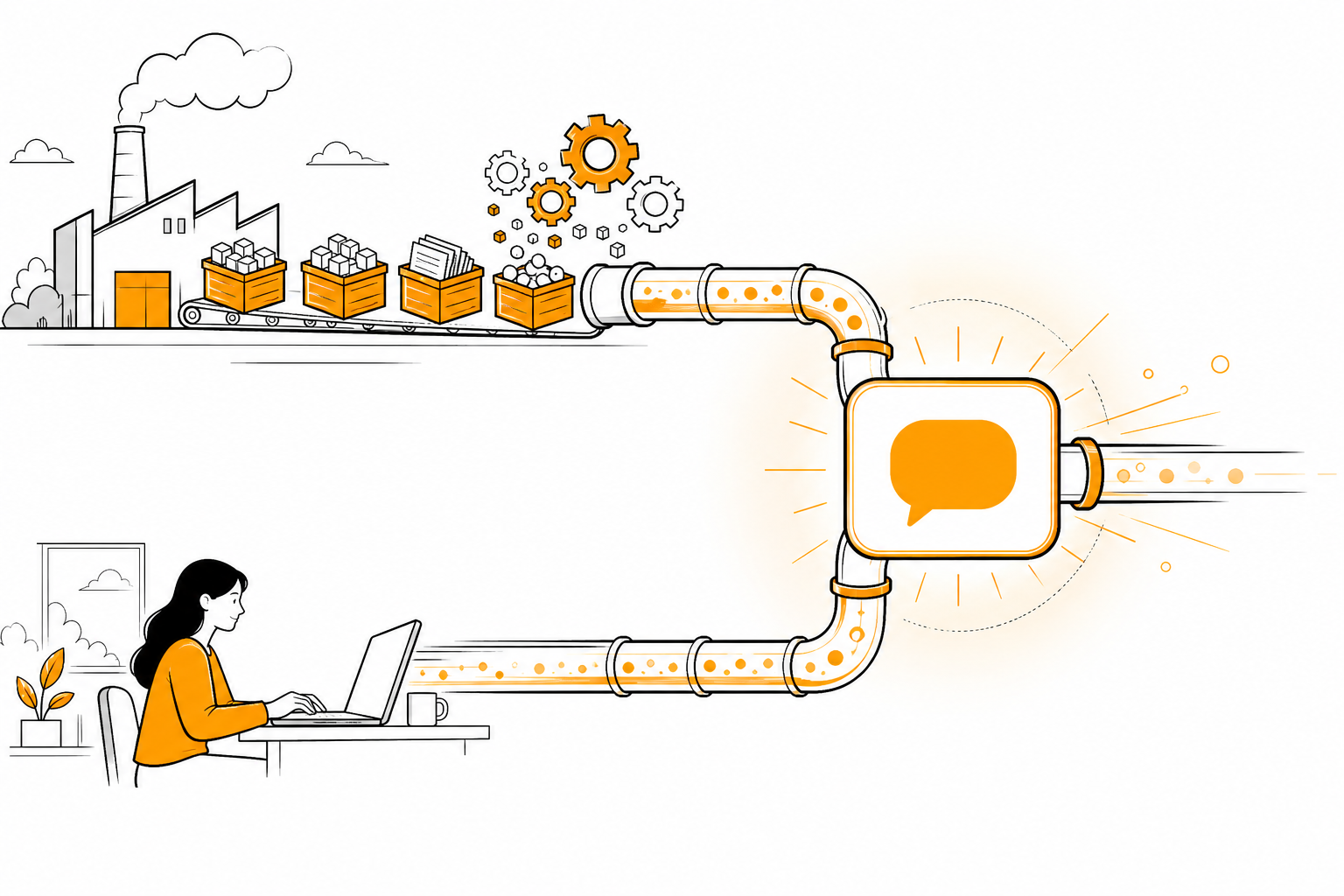
两条线交汇在那个聊天框/CLI 命令行的输入框里。你按下回车的那一刻,背后是几个亿训出来的模型在跑「下一个 token 预测」(上一篇讲过的那个机制),而你做的事是「问得好不好」。
整个 AI 时代普通人最值钱的能力就是:问得好。
这就是 niuxue.org 后面 4 个区要教你的——用 Claude Code 这样的 Agent 工具时,怎么把「问得好」做到极致,让 AI 真正替你干活。
—
认识 AI 板块结束 🍊
Section titled “认识 AI 板块结束 🍊”恭喜你看完了「认识 AI」4 篇。现在你应该清楚:
- ✅ AI 70 年怎么走到今天 → AI 是怎么走到今天的
- ✅ 大模型内部怎么转 → 大模型怎么工作的
- ✅ AI 圈在卷哪 5 个方向 → 现在 AI 圈在卷什么
- ✅ AI 端到端怎么训练 + 怎么被用 → 你正在看的这一篇
接下来进入实战环节——「入门」板块 5 篇会带你从「选哪个工具」一路到「第一次跑通」。从 Claude Code / 豆包 / ChatGPT 怎么选 开始。
评论
不记名、不需要注册——不要邮箱,不要手机号,不要任何身份信息,填个昵称就能留言。放心说。